코딩테스트 연습 - 전화번호 목록
전화번호부에 적힌 전화번호 중, 한 번호가 다른 번호의 접두어인 경우가 있는지 확인하려 합니다. 전화번호가 다음과 같을 경우, 구조대 전화번호는 영석이의 전화번호의 접두사입니다. 구조
programmers.co.kr
문제 설명
전화번호부에 적힌 전화번호 중, 한 번호가 다른 번호의 접두어인 경우가 있는지 확인하려 합니다.
전화번호가 다음과 같을 경우, 구조대 전화번호는 영석이의 전화번호의 접두사입니다.
- 구조대 : 119
- 박준영 : 97 674 223
- 지영석 : 11 9552 4421
전화번호부에 적힌 전화번호를 담은 배열 phone_book 이 solution 함수의 매개변수로 주어질 때, 어떤 번호가 다른 번호의 접두어인 경우가 있으면 false를 그렇지 않으면 true를 return 하도록 solution 함수를 작성해주세요.
제한 사항- phone_book의 길이는 1 이상 1,000,000 이하입니다.
- 각 전화번호의 길이는 1 이상 20 이하입니다.
- 같은 전화번호가 중복해서 들어있지 않습니다.
| phone_book | return |
| ["119", "97674223", "1195524421"] | false |
| ["123","456","789"] | true |
| ["12","123","1235","567","88"] | false |
입출력 예 #1
앞에서 설명한 예와 같습니다.
입출력 예 #2
한 번호가 다른 번호의 접두사인 경우가 없으므로, 답은 true입니다.
입출력 예 #3
첫 번째 전화번호, “12”가 두 번째 전화번호 “123”의 접두사입니다. 따라서 답은 false입니다.
풀이 1
해시를 활용하는 문제로, 해시 없이 문제를 풀게 된다면 입력받은 전화번호가 n개라면 시간복잡도가 O(n^2)으로 시간초과가 발생한다. O(1)만으로도 조회가 가능한 해시를 이용하여 충분히 풀이 가능하다.
Java에서 Hash를 이용한 자료구조 중 HashSet을 이용하였다. ( key-value의 형태가 아닌 단순 key만 저장하면 되기 때문에 HashMap은 비효율적이라고 생각했다.)
phone을 전부 set에 add하고, phone_book을 차례로 순회하면서 set에 phone으로 시작하는 값이 있는지 여부를 파악하도록 구현했다.
동일한 값이 아닌 접두사의 형태로 일치해야하는 것이기 때문에 phone을 substring()을 이용하여 길이를 한 개씩 길이를 늘려가며 찾도록 했다.
코드
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
Set<String> set = new HashSet<>();
for (String phone : phone_book) {
set.add(phone);
}
for (String phone : phone_book) {
for (int i = 1; i < phone.length(); i++) {
if (set.contains(phone.substring(0, i))) {
return false;
}
}
}
return true;
}
}
풀이 2
풀어 놓고 보니 뭔가 substring() 과정이 비효율적인 것 같아 보였다. 전화번호 길이는 입력받은 대로 이미 각각 정해져있는 상태이다. 예를 들어 3개의 전화번호의 길이가 각각 3, 6, 10이라고 할 때 substring()을 한다면, 1부터 10까지 하나하나 비교해볼 것이 아니라 전화번호의 길이인 3, 6, 10에서만 비교하면 된다. 다시 말해 반복문을 phone의 길이만큼 반복하는 것 대신, 전화번호들의 길이만큼만 조회하면 된다는 것!
처음 생각으로는 phone_book에 담긴 phone의 길이를 담는 리스트를 하나 생성하여 담은 뒤, 해당 리스트를 오름차순으로 정렬한 다음 비교를 하려고 했다. 하지만 정렬시키는 코드를 추가하면 효율성 테스트4에서 시간초과가 발생한다.
그렇다면 애초에 정렬된 상태로 저장하면 어떨까?라는 생각을 하게 되었고 일반적인 리스트 대신 TreeSet을 이용하기로 했다. T
reeSet은 값을 정렬된 상태로 유지하는 자료구조다.
코드 2
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
Set<String> set = new HashSet<>();
Set<Integer> lengths = new TreeSet();
for (String phone : phone_book) {
set.add(phone);
lengths.add(phone.length());
}
for (String phone : phone_book) {
for (int i : lengths) {
if (i >= phone.length()) {
break;
}
if (set.contains(phone.substring(0, i))) {
return false;
}
}
}
return true;
}
}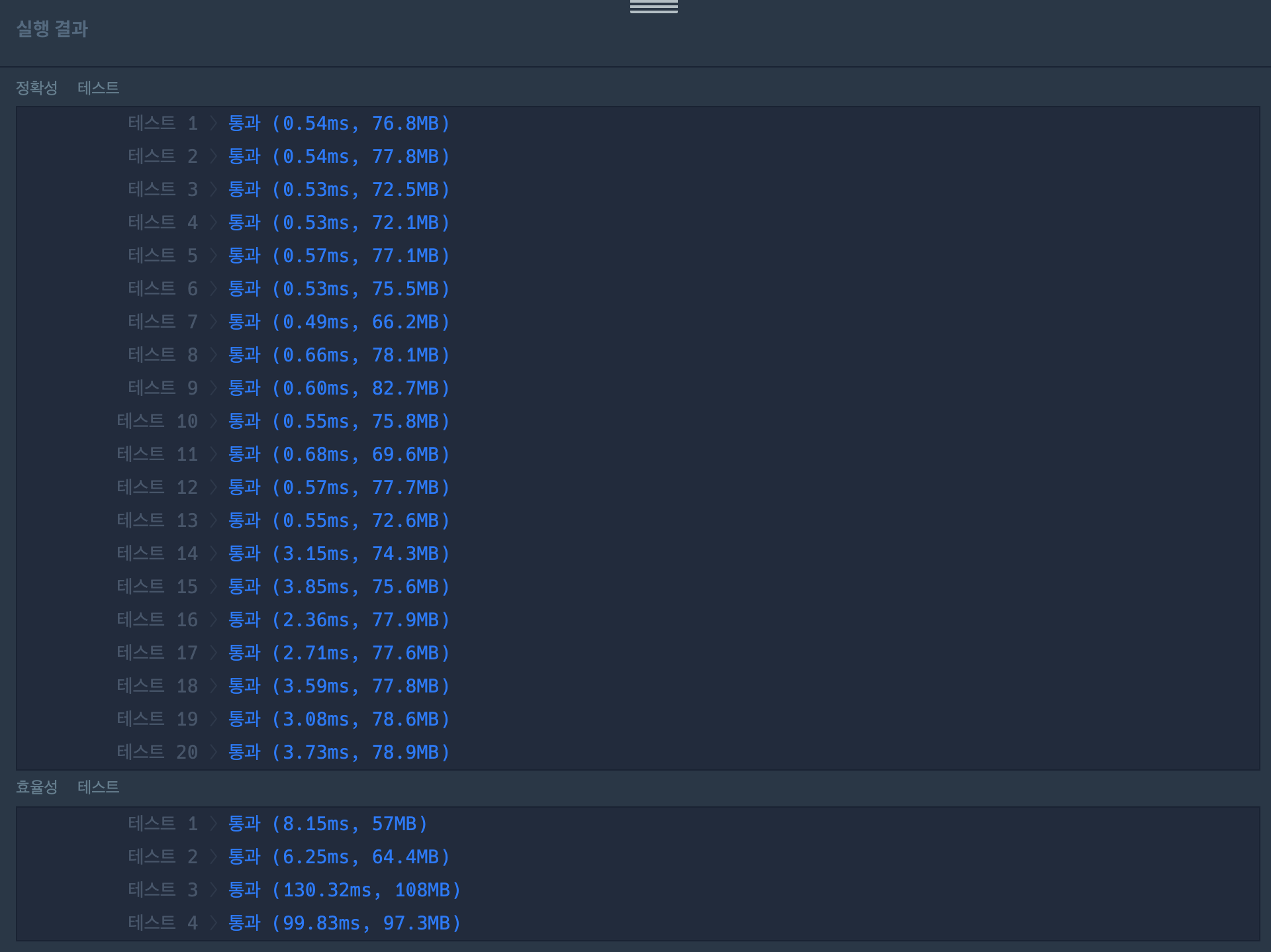
실제로도 더 효율적인 코드가 되었을까?
효율성 테스트 3, 4번을 기준으로 코드 효율성을 비교했을 때
풀이1의 경우는 각각 (241.72ms, 210MB), (188.34ms, 132MB)가 나온 반면
풀이2의 경우는 각각 (130.32ms, 108MB), (99.83ms, 97.3MB)로 절반 가까이 단축되는 결과를 확인할 수 있었다.
다만, 정확성 테스트 1 ~ 15의 경우는 풀이2의 결과가 풀이1의 결과보다 더 성능이 좋지 못했다. 크지 않는 데이터에 한해서 TreeSet에 값을 추가하고 정렬하는 과정이 for문을 더 도는 것보다 더 큰 오버헤드가 발생한 듯 하다.
'Tech > Problem Solving' 카테고리의 다른 글
| [프로그래머스] 프린터 - Java (0) | 2022.01.07 |
|---|---|
| [프로그래머스] 디스크 컨트롤러 - Java (0) | 2022.01.07 |
| [프로그래머스] 월간 코드 챌린지 시즌 3 - 빛의 경로 사이클 (Java) (0) | 2022.01.05 |
| [프로그래머스] 2017 카카오코드 본선 - 리틀 프렌즈 사천성 (Java) (0) | 2022.01.04 |
| [프로그래머스] 카카오 블라인드 리쿠르트 2018 - 셔틀 버스 (Python) (0) | 2021.04.20 |


